
.webp)
Data Masking vs. Anonymization: Key Differences





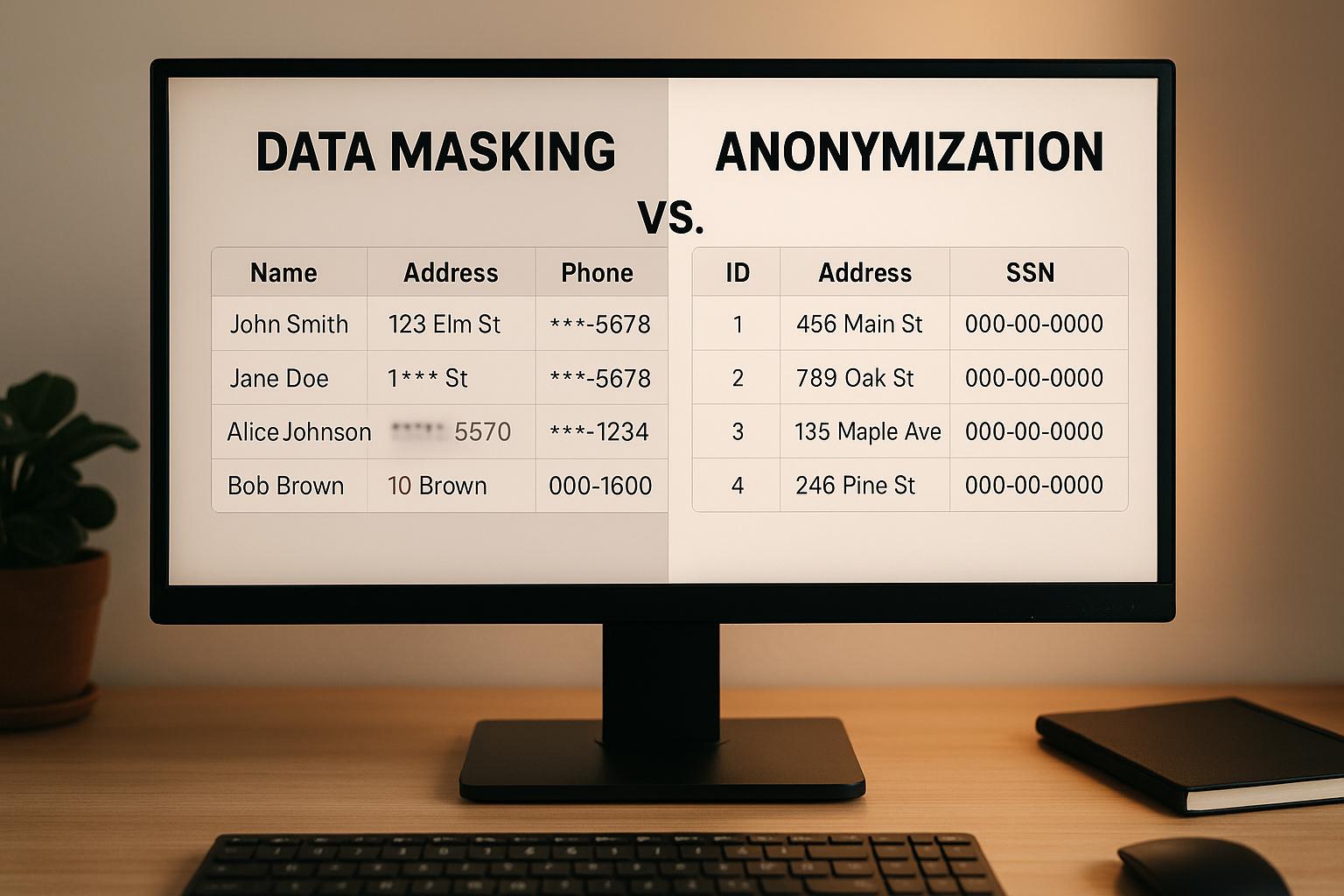
When it comes to protecting sensitive data, data masking and data anonymization are two distinct approaches tailored for different needs. Here's what you need to know:
- Data Masking: Replaces sensitive data with fake but realistic substitutes. It’s ideal for internal use, such as software testing, training, or analytics, where maintaining the structure and usability of the data is important. Masking is often reversible under controlled conditions, meaning it still qualifies as personal data under privacy laws like GDPR.
- Data Anonymization: Permanently removes all identifiers, ensuring individuals cannot be linked to the data. It’s best for external sharing, such as research or public datasets, where privacy is critical. Properly anonymized data is no longer considered personal data under regulations, making it easier to meet compliance.
Quick Comparison
| Feature | Data Masking | Data Anonymization |
|---|---|---|
| Reversibility | Often reversible with authorization | Irreversible |
| PII Status (GDPR) | Still considered personal data | Not considered personal data |
| Use Cases | Testing, training, internal analytics | Research, external sharing, compliance |
| Data Utility | Retains structure for usability | Retains analytical value |
Key Takeaway: Use masking for internal processes requiring realistic data and anonymization for external sharing or when privacy must be guaranteed. Both methods are essential tools for safeguarding data while meeting compliance requirements.
How Is Data Masking Different From Data Anonymization In Research? - The Friendly Statistician
What is Data Masking?
Data masking is the process of replacing sensitive information with realistic but fake data, ensuring its format remains unchanged. This "masked" version of the data looks authentic but keeps the original information secure, making it impossible for unauthorized users to uncover the true data.
Definition and Key Features
Data masking creates a fake yet functional version of an organization’s data. While the masked data works for operational purposes, it is completely disconnected from the original sensitive information.
"Once data is masked, you can't reverse engineer or track back to the original data values without access to the original dataset." - AWS
In most cases, data masking is irreversible, though certain methods, like deterministic encryption, allow for controlled reversibility under specific conditions.
Here are some of its key features:
- Realistic Substitutes: Original data is swapped with plausible alternatives. For instance, "John Smith" might become "David Jones", or a Social Security Number gets replaced with a random number that still fits the XXX-XX-XXXX format.
- Format Preservation: Masked data keeps the same structure as the original. A credit card number, for example, will still have 16 digits, and email addresses will retain their "@" and domain.
- Referential Integrity: Relationships between data remain intact. If a customer ID is masked in one table, it will be masked the same way across all related records.
- Semantic Consistency: Masked data follows logical rules. Salaries stay within realistic ranges, dates remain valid, and identification numbers adhere to predetermined patterns.
Next, let’s explore where data masking is most commonly used.
Common Use Cases for Data Masking
Data masking is essential in situations where maintaining data usability is crucial while protecting sensitive information. Here are some examples:
- Software Development and Testing: Developers need realistic datasets to test applications securely. According to a State of Data Compliance and Security Report, 66% of respondents reported using static data masking, and non-production environments often have up to 12 copies for every production copy.
- Real-World Success Stories:
- Molina Healthcare used data masking to safeguard protected health information in thousands of non-production databases. This ensured HIPAA compliance while reducing setup times, project schedules, and storage costs.
- Morningstar Retirement integrated data masking into its test data management strategy, cutting data provisioning hours by 70% and improving software quality by detecting defects earlier.
- Employee Training: Masked data allows organizations to simulate real-world scenarios for training purposes without exposing actual customer or business information.
- Internal Analytics and Research: Data scientists and analysts can analyze large, realistic datasets to generate insights without risking individual privacy.
- Secure External Collaboration: Masked data can be shared with partners or vendors without violating security policies or data residency regulations.
Data Masking Limitations
While data masking is a powerful tool for protecting sensitive information, it does have some limitations:
- Challenges with External Sharing: Retaining structural patterns in masked data might let attackers infer information when combining it with other datasets, making it unsuitable for public data releases.
- Potential Reversibility Risks: Although most masking techniques are irreversible, deterministic methods can pose risks if enough masked data points are exposed.
- Strict Format Constraints: Some data types, like credit card numbers that must pass Luhn validation or Social Security Numbers with specific regional patterns, require careful handling to ensure validity.
- Insider Threats: Masked data retains much of its original structure and context, which means insiders familiar with the data might still infer sensitive details.
Data masking works best in controlled, internal environments where maintaining functionality is essential. However, for scenarios requiring complete anonymity, techniques like anonymization might be a better fit.
What is Data Anonymization?
Data anonymization strengthens privacy by permanently removing personal identifiers, ensuring individuals cannot be identified - even when datasets are combined. Unlike data masking, which replaces sensitive details with realistic substitutes while maintaining the data's format, anonymization ensures the data cannot be traced back to specific individuals while still retaining its value for analysis.
"Data anonymization is a fundamental process in the realm of data privacy. It involves altering personally identifiable information (PII) in such a way that the individual to whom the data belongs cannot be identified directly or indirectly."
– Tonic.ai
Definition and Key Features
Properly anonymized data is untraceable, even if additional information is introduced. This transformation is defined by several important characteristics:
- Complete Identity Removal: All direct and indirect identifiers are permanently altered or removed. This includes obvious details like names and Social Security numbers, as well as quasi-identifiers that could reveal identities when combined.
- Regulatory Compliance: Anonymized data is no longer classified as personally identifiable under privacy laws like GDPR, allowing organizations to use it freely without needing individual consent.
- Preservation of Analytical Value: While identifiers are removed, the statistical properties of the data remain intact, enabling meaningful research, analysis, and business insights.
- Resilience Against Re-identification: Anonymized data is designed to resist identification attempts, even when merged with other publicly available datasets.
Next, let’s look at how anonymization is applied across various industries to protect privacy while enabling data sharing.
Common Use Cases for Data Anonymization
Anonymization is especially useful when privacy must be guaranteed for external sharing or public use. It eliminates re-identification risks in scenarios such as:
- Healthcare Research Collaboration: Hospitals can share patient data with researchers after removing fields that could identify individuals, enabling valuable studies without compromising privacy.
- Customer Analytics: Organizations can analyze anonymized customer data to improve recommendations, refine advertising strategies, and develop new products - all without requiring consent or risking privacy breaches.
- Public Policy Development: Governments can use anonymized datasets, like crime statistics or social media trends, to shape policies without exposing personal information.
- Academic Research: Universities and researchers rely on anonymized datasets for large-scale studies while safeguarding participant identities.
- Public Data Releases: When making datasets publicly available for transparency or research, anonymization ensures sensitive details remain protected.
Data Anonymization Limitations
While anonymization provides strong privacy safeguards, it comes with certain challenges and trade-offs:
| Benefits of Anonymization | Drawbacks of Anonymization |
|---|---|
| Prevents identification of individuals | Can limit the depth of analysis by removing key identifiers |
| Facilitates safe data sharing for research and analysis | Requires specialized tools and expertise, increasing complexity and cost |
| Eases compliance with privacy laws | Can be time-consuming and resource-intensive for large datasets |
| Protects sensitive information from unauthorized access | May not be effective for highly sensitive or unique data |
Additional considerations include:
- Reduced Data Utility: Removing or altering identifiers can limit the insights that can be drawn from the data.
- Re-identification Risks: Sophisticated attackers might still match anonymized data with other datasets to identify individuals.
- Complex Implementation: Achieving true anonymization requires advanced knowledge of privacy techniques and specialized tools.
- Scalability Issues: Anonymizing large datasets while retaining their analytical value can demand significant resources.
Emerging technologies are beginning to address some of these challenges. For instance, AI-generated synthetic data preserves statistical properties without using original data points, homomorphic encryption enables analysis on encrypted data, and federated learning allows machine learning models to train locally without transferring sensitive information.
Data anonymization works best when organizations need to share data externally, comply with strict privacy regulations, or eliminate re-identification risks entirely. However, it may not be the optimal solution for internal use cases where detailed, functional datasets are essential.
sbb-itb-5f36581
Data Masking vs. Anonymization: Key Differences
Both data masking and anonymization aim to protect sensitive information, but they serve different purposes and are applied in distinct ways. Picking the right approach depends on your specific needs.
The primary distinction lies in their relationship to each other. Chiara Colombi, Director of Product Marketing at Tonic.ai, explains it clearly:
"Data anonymization encompasses a variety of techniques and approaches. It is synonymous with the term data de-identification. Both data anonymization and data de-identification are umbrella terms to refer to a collection of more specific techniques such as data masking or data redaction. Comparing data anonymization vs data masking does not fully make sense, since data masking is a form of data anonymization."
Although technically connected, these methods are often discussed as separate strategies because they address different business needs and regulatory requirements.
Comparison Table: Data Masking vs. Anonymization
| Feature | Data Masking | Data Anonymization |
|---|---|---|
| Reversibility | Often reversible with proper authorization | Irreversible; data permanently altered |
| PII Status (GDPR) | Still considered PII due to potential reversibility | Not considered PII when correctly implemented |
| Primary Purpose | Realistic data for testing, development, training, and internal access control | Privacy protection for external sharing, research, and long-term storage |
| Data Utility | Maintains structural fidelity for realistic substitutes | Retains functional integrity for effective analysis |
| Typical Use Cases | Software testing, demo environments, role-based access control | Research collaboration, business analytics, public data releases |
These differences highlight how each method is tailored to specific scenarios.
Reversibility and Data Utility
One of the biggest practical differences between these two methods is reversibility. Data masking allows for a pathway back to the original information, often using encryption keys or lookup tables. This reversibility ensures that masked data remains classified as PII under GDPR, making it suitable for internal operations where occasional access to the original values is necessary.
Anonymization, on the other hand, permanently alters the data, ensuring that individuals cannot be identified, even when combined with other datasets. While this approach offers stronger privacy protections, it also limits flexibility for internal use.
Both methods preserve data utility, but they do so in different ways. Masked data retains the structural characteristics of the original dataset, making it ideal for applications like software testing, where realistic data formats are needed. Anonymized data, however, focuses on retaining statistical properties and analytical value, which is critical for research and analysis while ensuring privacy.
Internal vs. External Use Cases
The choice between masking and anonymization often comes down to how the data will be used.
Data masking works best for internal processes where realistic data is needed without exposing sensitive information. For example, customer-facing systems might display partially masked credit card numbers to protect full details. Similarly, development teams can use masked production data to test applications without risking the exposure of actual customer information.
Data anonymization is the go-to option for external sharing, especially when privacy must be guaranteed. A common example is medical research: hospitals sharing patient data with research institutions must anonymize the information to remove all identifiers while preserving the insights needed for studies. Financial institutions might anonymize transaction data before sharing it with partners for fraud detection research.
The regulatory implications are also significant. Anonymized data, when implemented correctly, often falls outside the scope of strict privacy regulations like GDPR and HIPAA, simplifying compliance for external sharing. Masked data, because of its potential reversibility, remains subject to full regulatory requirements.
How to Choose Between Data Masking and Anonymization
Choosing between data masking and anonymization depends on your specific business needs, regulatory obligations, and how you plan to handle the data. Here's a breakdown of the key factors to help you decide which approach fits your objectives.
Factors to Consider When Deciding
-
Data Sensitivity:
If you're dealing with highly sensitive information - like medical records or financial data - irreversible anonymization is the safer choice. For less critical data, masking is often sufficient. -
Purpose:
Use anonymization when you need to completely remove identities, such as for public datasets or research purposes. Masking works better for controlled, internal use where some level of data structure needs to be retained. -
Regulatory Requirements:
Both methods can help meet regulations like GDPR, HIPAA, and CCPA. However, anonymized data, when properly and irreversibly altered, falls outside the scope of these regulations.
"Anonymized data is no longer personal data, so it is generally outside the scope of regulations such as GDPR or CCPA. This makes it simple for companies to be exempt from regulations and to share data externally. The anonymization must, however, be strong and irreversible to be exempted." - Bacancy Technology
-
Reversibility Needs:
Anonymization is a one-way process, meaning the original data cannot be restored. Masking, on the other hand, is often reversible for authorized internal use. -
Security Level:
Anonymization significantly reduces the risk of re-identification. Masking, while effective at protecting data, depends on the strength of the method used to preserve its structure.
Real-World Examples for Each Method
Looking at practical applications can help clarify how these methods are used:
-
Pharmaceutical Companies:
When sharing patient data from clinical trials, anonymization is often the go-to method. This allows companies to analyze drug efficacy and side effects while sharing insights for public health improvements - all without compromising patient privacy. -
Customer Service Applications:
Data masking is commonly used by internal teams and AI-driven helpdesks. For example, showing only the last four digits of a credit card number allows customer service representatives to resolve issues without exposing the full sensitive information. -
Software Development and Training:
Masked data is widely used in software development, testing, and training environments. It provides realistic scenarios for testing and sales demonstrations while safeguarding actual client or sensitive information.
Building Your Data Protection Strategy
A balanced approach often works best. Use masking for internal operations and anonymization for external data sharing. If reversible access to data is necessary, consider implementing tokenization. Strengthen your strategy with robust security tools and ensure your data protection practices are well-documented to meet compliance requirements.
Conclusion
With data breaches surging by 156% and the average cost of a breach reaching $4.45 million, deciding between data masking and data anonymization is a critical step for safeguarding your organization and ensuring compliance.
Data anonymization provides the strongest protection by permanently removing all identifying details, making it ideal for external data sharing and research. On the other hand, data masking creates realistic yet protected datasets that are perfect for internal operations like development, testing, and training.
"Data masking is vital for two primary reasons: protecting data from internal and external threats, and complying with data protection regulations." – Jonathan Darley, Security and Data Engineer, Accutive Security
Key Takeaways
To effectively protect your data, a dual-approach strategy tailored to internal and external needs is often the best solution. Use anonymization for external sharing or when handling highly sensitive information that requires permanent protection. Opt for masking in internal processes where maintaining data utility and reversibility is essential.
The statistics speak volumes: 75% of enterprises report rising volumes of sensitive data in non-production environments, and 91% express heightened concerns about associated risks. These numbers underline the urgent need for robust data protection measures.
An effective strategy should include identifying sensitive data through discovery tools, enforcing role-based access controls, and implementing continuous monitoring. Whether you choose masking, anonymization, or a combination of both, consistency is key. Regularly update your protection measures to keep pace with evolving threats.
Investing in solid data protection practices doesn’t just reduce breach risks - it also simplifies compliance and strengthens customer trust.
FAQs
What are the differences between data masking and anonymization when it comes to GDPR compliance?
When it comes to privacy regulations like GDPR, data masking and anonymization serve different purposes, each with its own strengths.
Data masking involves modifying sensitive information so that it becomes unreadable but still functional for tasks like testing or analysis. Think of it as disguising the data to protect personal details while keeping it useful for internal processes.
Anonymization, however, goes a step further. It permanently removes or alters personal identifiers, ensuring the data can no longer be traced back to an individual. Once anonymized properly, the data is no longer classified as personal data under GDPR, freeing it from those regulatory requirements.
The choice between these two methods depends on your needs. If you're working with data internally, masking is often the way to go. But if you're planning to share data externally or make it available publicly, anonymization is the safer and more compliant option.
When should you use data masking instead of data anonymization, and vice versa?
Data masking works well when you need to keep the structure and usability of data intact for tasks like testing, troubleshooting, or analysis. It hides sensitive details while preserving the original data format, making it especially useful in cases where reversible access to the original information is needed.
On the other hand, data anonymization is a better choice when the primary goal is to protect sensitive information. By permanently removing identifiable elements, anonymization ensures the data cannot be linked back to individuals. This approach is crucial for meeting regulatory requirements and securely sharing data with third parties.
What are the risks and challenges of using data masking and anonymization?
When it comes to protecting sensitive information, both data masking and anonymization have their challenges and risks. For instance, outdated or weak data masking techniques - such as easily breakable algorithms or compromised encryption keys - can leave your data vulnerable to breaches. Similarly, anonymization isn't foolproof; incomplete or poorly executed processes can lead to re-identification, especially when combined with other datasets.
Another factor to consider is how these methods can impact the usefulness of your data. While they’re effective at safeguarding sensitive information, they often come at the cost of reduced accuracy or usability for analysis or day-to-day operations. Choosing the right method requires a careful balance between protecting data and maintaining its utility, all while ensuring compliance with relevant regulations.
Related Blog Posts
Get new content delivered straight to your inbox

The Response
Updates on the Reform platform, insights on optimizing conversion rates, and tips to craft forms that convert.




Drive real results with form optimizations
Tested across hundreds of experiments, our strategies deliver a 215% lift in qualified leads for B2B and SaaS companies.
