
.webp)
Third-Party Risks: Incident Response Guide






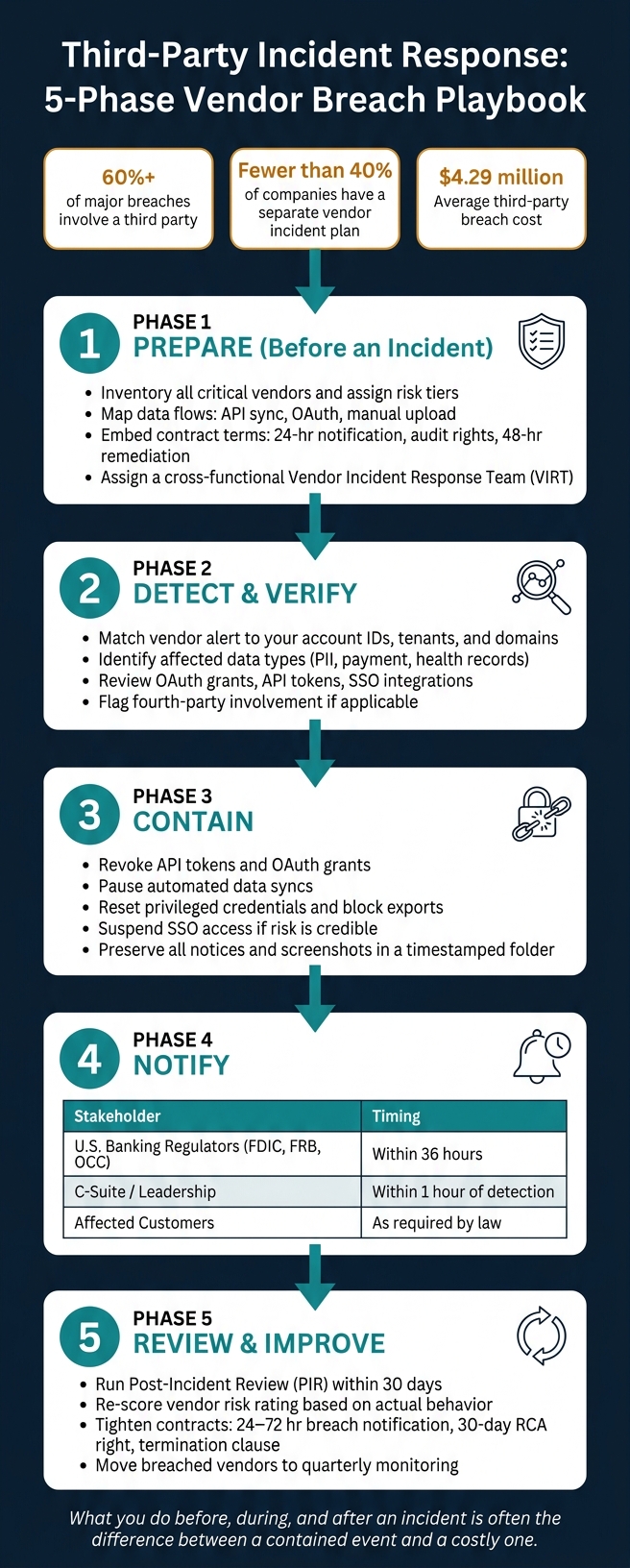
A vendor issue can hit your data, systems, and legal deadlines at the same time. More than 60% of major breaches involve a third party, yet fewer than 40% of companies have a separate plan for vendor incidents.
If I had to boil this down, I’d say this: know which vendors matter, lock in incident terms before trouble starts, assign owners, move fast to contain exposure, and review every incident for gaps. That’s the core of a third-party incident response plan.
Here’s the article in plain English:
- Third-party incidents are different because I don’t control the vendor’s logs, timeline, or fixes.
- Preparation drives response speed: I need a vendor list, data-flow map, contract terms, and named contacts before an incident happens.
- The plan should be short and clear on who leads, who talks to the vendor, who handles legal review, and who approves shutdowns.
- First response steps matter most: confirm scope, check affected data and integrations, revoke tokens, pause syncs, reset shared access, and save evidence.
- Legal and customer notice can move fast. In banking, some incidents may need regulator notice within 36 hours.
- After the incident, I should review what failed, update vendor risk scores, tighten contract terms, and increase monitoring if needed.
A few facts stand out: the average third-party breach cost reached $4.29 million, and AT&T paid $13 million after a vendor breach affected 8.9 million wireless customers. That’s why vendor response can’t be handled as an afterthought.
If a vendor touches customer data, payments, healthcare records, cloud access, or lead forms, it should already be in scope for my incident plan.
Third-Party Incident Response: 5-Phase Vendor Breach Playbook
BSidesSF 2025 - Effective Handling of Third-Party Supplier Incidents (Kasturi Puramwar)
sbb-itb-5f36581
Build the Foundation Before an Incident Happens
Solid incident response starts long before anything goes wrong. Fast containment comes from prep.
Inventory Critical Vendors and Data Flows
You can’t protect what you haven’t mapped. Start with every vendor that touches sensitive data - customer leads, payment information, protected health records, or credentials. Then sort each one into a risk tier.
For each critical vendor, build a data-flow table. Spell out what the vendor supports, what data it can reach, how that data moves - API sync, OAuth, or manual upload - and what breaks if the service is down for 24 hours.
| Vendor Category | Example Systems | Data Types | Business Impact of Failure |
|---|---|---|---|
| Customer/Lead | CRM, marketing and sales tech stack platforms | Names, emails, lead source | Sales pipeline stalls; revenue loss |
| Operations | Case Management, ERP | Protected addresses, youth records | Legal/compliance risk; service delivery stops |
| Financial | Payment Processors, Payroll | Credit card data, bank info | Fraud risk; cash flow delays; staff unpaid |
| Infrastructure | Cloud Storage, SSO, IT Support | Credentials, sensitive files | Total system lockout; data exposure |
That inventory gives responders what they need fast: impact, ownership, and shutdown options in minutes.
And don’t stop with direct vendors. Map key subcontractors and cloud dependencies too - the outside providers your vendors depend on - because that’s often where the root cause sits.
This map should make three things plain:
- who owns the vendor
- what data is exposed
- what fails first
Put Incident Terms Into Vendor Contracts
A vendor’s willingness to help during an incident is only as strong as the contract. Phrases like “best efforts” and “commercially reasonable time” sound fine until the clock is ticking. Then they give vendors room to stall.
Contract language shapes response speed:
| Clause Type | Stricter Language | Looser Language | Practical Impact |
|---|---|---|---|
| Notification Timing | "Notify within 24 hours of discovery" | "Best efforts" or "as soon as practicable" | Stricter terms help meet tight breach-notification deadlines; loose terms cause delays |
| Detail Level | "Provide list of affected users, data fields, and mitigation steps" | "Provide a summary of the incident" | Detailed data enables immediate impact assessment; summaries lack actionable forensic info |
| Audit Rights | "Right to perform an independent audit or review forensic logs" | "Vendor will provide a summary of their own internal investigation" | Independent access prevents vendors from concealing scope |
| Remediation | "Remediate within 48 hours or provide a workaround" | "Vendor will work to resolve in a timely manner" | Specific timelines create leverage; vague terms leave the business waiting |
These clauses shape how fast you can verify scope, notify affected parties, and push for remediation.
Also require vendors to disclose their key subcontractors and cloud dependencies, and to tell you when those dependencies change.
Those terms become your playbook for notification, access, and remediation when an incident hits.
Define Roles, Triggers, and Ownership
Do not argue about ownership in the middle of an incident. That call needs to be made ahead of time.
Set up a cross-functional Vendor Incident Response Team (VIRT) with IT Security, Legal/Compliance, Procurement/TPRM, Executive Leadership, and Communications. Every role should have a named backup and an after-hours contact - not just a generic help desk inbox - so a critical vendor issue reaches the right person at any hour.
| Feature | Centralized (VIRT) | Distributed (Business Units) |
|---|---|---|
| Speed | High; dedicated team knows the playbook | Low; requires gathering disparate stakeholders |
| Consistency | High; uniform response and documentation | Low; different units may handle vendors differently |
| Accountability | Clear; single point of contact (Incident Lead) | Diffuse; ownership can be ambiguous in cross-unit breaches |
Escalation triggers should tie back to vendor criticality tiers, not gut feel. A Tier 1 (Critical) vendor breach - one involving sensitive data or a core integration - should trigger C-suite notification within 1 hour. Time-sensitive actions like revoking API tokens, forcing password resets, or suspending data intake should be pre-authorized, so nobody is stuck waiting for sign-off during a live incident.
Run one annual tabletop exercise built around a high-pressure vendor breach scenario. It’s one of the fastest ways to spot gaps in decision rights and backup coverage.
With vendors mapped, terms set, and owners assigned, the next step is turning those inputs into a written response playbook.
Create a Third-Party Incident Response Plan
Turn your vendor inventory into a written response plan. Keep it tight and usable. When pressure hits, nobody wants a long policy doc. They need a plan that says what happens next, who does it, and when it starts.
Each phase should have a clear owner and a clear trigger. That way, the team can move fast instead of debating roles in the middle of an incident.
Core Plan Elements and Team Structure
Keep the plan short and operational. It should answer six questions fast: who leads, who decides, who communicates, who handles legal, who speaks with the vendor, and who stores evidence.
Assign each function to a named role:
- Incident Coordinator - owns the timeline and keeps one incident log for evidence
- IT Security Lead - handles technical containment, such as token revocation and access blocks
- Vendor Owner - manages the vendor relationship and escalates through the right contact
- Legal/Privacy Reviewer - decides whether regulatory notice duties apply
- Communications Lead - controls all external messaging, including customer notices
- Executive Decision Maker - approves high-impact actions like pausing integrations or suspending a vendor
Once ownership is set, define the severity thresholds that trigger action.
Severity Levels and Escalation Paths
Classify incidents based on data sensitivity, customer impact, regulatory exposure, and service disruption.
| Severity Level | Data/Operational Impact | Response Time Trigger | Required Actions |
|---|---|---|---|
| Critical | Regulated/high-risk data exposed; core services down during deadlines | 1 hour | C-suite notification; revoke API tokens; rotate shared secrets; suspend data intake; regulatory assessment |
| High | Credible unauthorized access; major outages blocking service delivery | 4 hours | Security team escalation; legal review within 24 hours |
| Medium | Limited data exposure; partial outage; suspicious signals without confirmation | 1 business day | Internal investigation; vendor status request; monitor for escalation |
| Low | Minor issues; near-misses; vendor maintenance failures with low impact | 1 week | Review at next scheduled vendor check-in; document in risk log |
After those thresholds are in place, map every lead-capture workflow that could widen the scope of the incident.
Include Lead Capture and Form Workflows in Scope
Lead capture workflows belong in scope. If your team uses Reform, document what each form collects, where submissions go, which integrations are live, and which logs and analytics are available to help scope the issue.
That kind of detail can save time early on, before the response moves into containment.
Execute the Vendor Incident Playbook
Verify the Incident and Assess Impact Quickly
Once the playbook is triggered, start by confirming the scope and impact. Check the incident against the vendor's official notice, then match that notice to your account IDs, tenants, and domains. Not every vendor alert touches your data.
After that, go straight to your vendor inventory. Find out what data the vendor handles, which systems connect to it, and whether any regulated data, such as PII or sensitive customer records, was in scope. Review active OAuth grants, API tokens, SSO integrations, and automated data syncs. If a fourth party caused the issue, flag that right away because it changes your recovery options.
Large vendor breaches can ripple across many customers fast, so scoping the issue early is a big deal.
If the incident is confirmed, shift from assessment to containment without delay.
Contain Exposure and Coordinate With the Vendor
Once you know the impact, contain the exposure. Revoke tokens, pause syncs, reset privileged credentials, and block exports. If the risk looks credible, suspend SSO access to the affected vendor until you get a verified fix.
Assign one person, the Vendor Owner, to manage all communication with the third party and track every commitment the vendor makes. That keeps the message clean and cuts down on mixed signals or missed updates. If the vendor stops responding, escalate straight to their security contact or account leadership. Don't sit and wait.
Preserve all notices, emails, and screenshots right away in a restricted, timestamped folder.
Handle Notifications, Documentation, and Service Decisions
While containment is moving, legal review and documentation need to start at the same time. Keep one timestamped incident log for every action, decision, and communication.
Preparation turns response from panic into process.
Bring in Legal within the first few hours to review notification duties. U.S. banking regulators (FDIC, FRB, OCC) require notification within 36 hours for specific security incidents. The table below shows each notification path, its trigger, timing, and required content:
| Stakeholder | Common Triggers | Timing | Required Content |
|---|---|---|---|
| Regulators (U.S. Banking) | Specific security incidents (FDIC, FRB, OCC) | Within 36 hours | Incident type and scope |
| Customers | Exposure of PII or protected records | As required by law | What happened, data involved, protective steps |
| Leadership (C-Suite) | Critical/Tier 1 vendor incident | Within 1 hour of detection | Business impact, containment status, legal risk |
| Partners/Funders | Shared data environment or contractual requirements | Per SLAs or within 24 hours | Scope of impact, expected recovery timeline |
| Internal Teams (Security/Legal/Comms) | Any confirmed or suspected incident | Immediate (Security/IT); 4–24 hours (Legal/Comms) | Technical indicators, containment actions, talking points |
Once initial notice duties are in motion, decide whether the vendor should stay online. Make that call early: continue, limit, or suspend the vendor relationship. Before you turn any integration back on, verify the fix and watch for unusual activity for at least one week.
Review, Improve, and Reduce Future Vendor Risk
Run a Post-Incident Review That Produces Changes
After containment and notifications, move from response into remediation.
Once the immediate response ends, run a post-incident review (PIR) within 30 days. Treat it like a corrective action review, not a box-checking exercise. The goal is simple: find the gaps, assign fixes, and make sure each fix has an owner.
Look closely at a few points that often get missed. Did the vendor know about the incident before they told you? Did your internal escalation reach the right people fast enough? Did your first impact assessment catch the full scope of affected data? And during the investigation, where did evidence go missing?
Metrics help here because they give you a baseline instead of a gut feeling. Track items like internal acknowledgment time and leadership-summary time so you can measure whether the next response moves faster.
The June 2026 Instructure Canvas breach showed how scope mistakes can grow when lower-tier accounts share infrastructure with enterprise tenants.
While the case is still fresh, record the root cause, evidence, and corrective actions in the vendor file. That file should shape future decisions about the vendor, from review cadence to contract terms.
Update Risk Ratings, Controls, and Vendor Terms
Use what you learned to reset both risk and vendor terms.
After the PIR, re-score the vendor's risk rating based on what happened in practice, not what looked good on paper. That includes their transparency, how fast they disclosed the issue, and how well their remediation worked. If the incident exposed a gap that sits outside your organization's risk appetite, update the risk register right away.
This is also the moment to tighten the contract. Push for:
- breach notification windows of 24–72 hours
- the right to receive a root cause analysis within 30 days
- the right to terminate for cause after a material breach
If a vendor has already gone through a breach, move them to quarterly monitoring.
The table below compares common post-incident actions by cost, speed, and risk reduction potential:
| Post-Incident Action | Implementation Cost | Speed of Execution | Risk Reduction Potential |
|---|---|---|---|
| Contract Amendment | Low (Legal fees) | Slow (Renewal cycle) | High (Legal/financial protection) |
| Added Monitoring | Medium (Tools/staff) | Fast | Medium (Earlier detection) |
| Process Change | Low (Internal) | Medium | Medium (Operational resilience) |
| Vendor Replacement | High (Migration) | Very slow | High (Eliminates specific risk) |
Added monitoring and process changes are often the faster wins. Contract amendments and vendor replacement take more time, but they can give you stronger protection. Use the facts from the incident to pick the lowest-cost fix that closes the gap.
Conclusion: The Basics of Third-Party Incident Readiness
Those changes turn a one-off incident into a stronger control baseline.
Third-party incident readiness comes down to five basics: map critical vendors, document data flows, write response duties into contracts, keep a clear playbook, and use each incident to close gaps.
For critical workflows like website forms and intake, your plan should include a way to pause integrations or temporarily stop intake so data does not keep flowing into a compromised environment. What you do before, during, and after an incident is often the difference between a contained event and a costly one.
FAQs
How do I know which vendors are critical?
Assess vendors based on three things: the data they can access, how much your day-to-day work depends on them, and the business impact if something goes wrong.
Start with the vendors that handle sensitive information or support mission-critical functions. A simple way to size up the risk is to ask: if this vendor were down for a full day, which processes would stop, and how would that affect customers or internal operations?
Then group vendors into clear tiers so your team knows how to respond and when to escalate:
- Tier 1 (Critical): Vendors whose outage or failure would stop key business functions or create serious customer impact
- Tier 2 (High): Vendors that support important work but may have workarounds for a short period
- Tier 3 (Medium/Low): Vendors with lower impact and less urgent response needs
This tiering helps set response expectations and escalation paths.
What should I do first in a vendor breach?
First, check the facts with the vendor itself, not with secondhand reports. At the same time, bring in your incident response team to figure out your exposure, including which systems, data, and integrations are affected.
Open a clear line of communication with the vendor and start containment at once. That can mean isolating affected systems or revoking the vendor’s access credentials.
When does a third-party incident require notification?
Notification depends on your contracts and the rules that apply to your data and industry.
Review your obligations when a vendor incident affects your data, day-to-day operations, or customers. Common timelines include 24 to 72 hours under many contracts, 72 hours under GDPR, 60 days under HIPAA, 4 hours under DORA, and 36 hours for certain U.S. banking incidents under FFIEC guidance.
Related Blog Posts
Get new content delivered straight to your inbox

The Response
Updates on the Reform platform, insights on optimizing conversion rates, and tips to craft forms that convert.




Drive real results with form optimizations
Tested across hundreds of experiments, our strategies deliver a 215% lift in qualified leads for B2B and SaaS companies.
